分布式日志-基于Bookkeeper的分布式日志实现
上篇文章介绍了Bookkeeper,但是Bookkeeper提供的是有界的日志Ledger,和实际的分布式日志还有一定的GAP。本文将介绍如何利用Bookkeeper实现一个简单可单点读写的分布式日志系统。
设计目标
- 消息特性:
- 一个日志可以包含有序的Message集合,每个Message都有唯一的MessageID标识。
- 颁发给用户MsssageID保证单调递增。
- 读写保证:
- 写入成功后,保证可读;写入成功前,不可读。(read happen after write)
- 写入对象保证跨节点的全局单例。新的WriteHandler的开启将Fence的WriteHandler。
- 可以通过MessageID指定读取位置。
无界日志DLOG
Bookkeeper提供了有界日志Ledger,我们可以基于Ledger组织出无界日志DLOG,DLOG由两部分组成:
- Meta:维护了DLog的状态与配置以及对应LedgerList,形式上类似于日志的日志。
- Ledger:即Bookkeeper的Ledger。
其结构如下图所示:
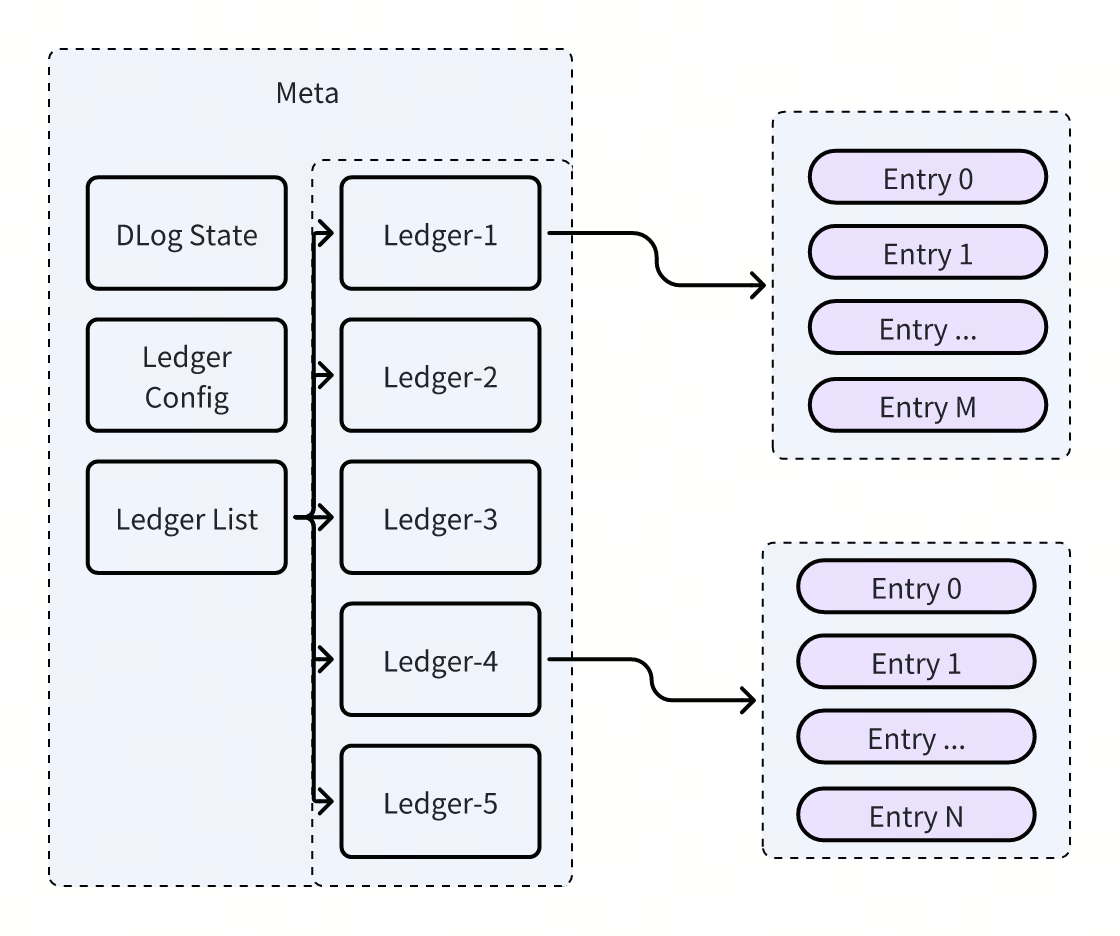
当单个Ledger写满时,或者客户端出现了Crash时,会生成一个新的后继的Ledger(即Rotation),新数据将会Append到这个新的Ledger上,从而实现一个无界的日志。
数据结构
MessageID
DLOG维度下,每个写入成功的消息都具备有唯一的MessageID,MessageID由三部分组成,MessageID的顺序关系由该三部分依次组成的字典序决定:
- LedgerID:Bookkeeper集群生成,同一个Bookkeeper内集群单调递增。
- EntryID:Bookkeeper集群生成,同一个Ledger内单调递增。
- BatchIdx:DLOG客户端生成,用于批量写优化,同一个Entry内单调递增。
有没有发现很熟悉,这不就是Pulsar的MessageID吗?对了,Pulsar的Broker上实现的MLedger本身就是一个分布式日志。
Message
Message的Binary表达由以下几部分组成:
- Magic:1bytes,用于标识版本,方便未来实现新日志结构的兼容升级。
- Attr:1bytes,(位表达)消息属性标识,未来用于标记需要底层存储系统识别的标记。
- Key: 消息体对应的键。
- Payload:消息体。
- Headers [key, val, key, val….]:消息体Header。
架构与实现
DLOG客户端负责维护DLOG的Meta信息,以及对应的Bookkeeper WriteHandler。 因此DLOG自身也是一个Leaderless系统,需要客户端自行解决分布式的一致性共识问题。同时,DLOG客户端同时需要维护Meta和数据的一致性:
- Meta的一致性:DLOG客户端需要保证Meta的一致性,KV Meta Storage的相关原子性操作实现,主要是CAS。
- 数据的一致性:由Bookeeper的客户端实现。
类似于Bookkeeper,我们可以将需要达成共识的场景拆成以下两个:
- 在正常运行的场景下,WriteHandler是全局单例的,因此不存在分布式共识问题。
- 在系统需要抢占正在写入日志的写入权时,同时存在两个WriteHandler,需要处理脑裂问题。由于是抢占式的实现,新的WriteHandler的开启将Fence的WriteHandler。
在出现脑裂的情况下,我们可以进一步细分:
| 对象 | In Using DLog Writer(只有一个) | Incoming DLog Writer(可能由N个) |
|---|---|---|
| 场景1 | 正在Rotation;有新老两个Ledger正在写入。(处于延迟考虑,在完成Rotation之前,允许老的Ledger继续写入) | 尝试打开 |
| 场景2 | 未Rotation;只有最新的Ledger正在写入。 | 尝试打开 |
场景1可以覆盖场景2,因此我们只需要处理场景1即可。其实现如下:
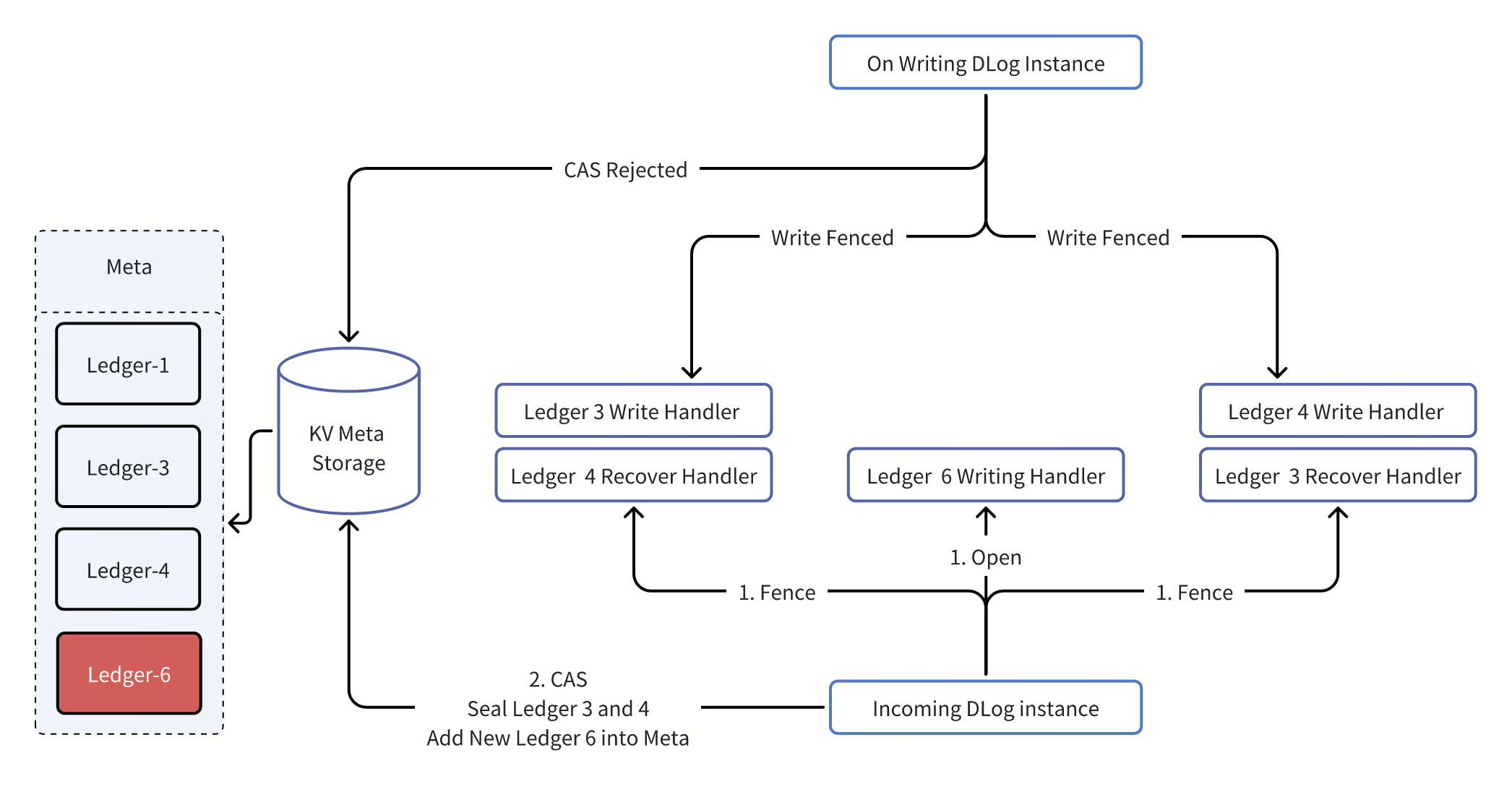
- 老的写入者一但感知到以下两种情况,就可以永久让渡出写入权给新写入者。
- 对Meta数据的CAS被拒绝。
- 对任意一个Ledger的Append操作被Fence。
- 新的写入者需要同时Fence老的写入者的最后两个Ledger,并且同时对Meta数据进行一次完整的CAS操作。才能对新Ledger开始执行写操作。这个过程伴随一段时间的写中断,具体时间取决于Ledger Fence操作的恢复速度。
可用性
通过上面对DLOG的介绍,我们可以知道DLOG只是提供了一个客户端,其可用性取决于Bookeeper,和MetaStorage的可用性。 针对 E=3;W=3;A=2的场景,4Bookie。同时出现一个Bookie宕机或者客户端宕机的场景,我们做下分析:
| Operation | 可用性 | 说明 |
|---|---|---|
| Create | Y | 有充足的Bookie可以使用,可用 |
| Open | Maybe | 1. 新DLOG,有充足的Bookie可以使用,可用 2. 不是新DLOG,依赖Fence机制,有可能需要等到Bookie恢复,见上面对Recovery的分析 |
| Append | Y | 1. 通过Ensemble Change恢复,可用 2. 如果客户端宕机,通过Rotation实现恢复,可用 |
| Read | Y | 有存活的Bookie,可用 |
| Shrink | Y | 只和Meta交互,可用 |
| Rotate | Y | 有充足的Bookie可以使用,可用 |
综上所述,DLOG具备极强的高可用性,除非极端的Recovery场景,否则即使在Bookie单节点宕机+客户端宕机的场景下,都能够保证可用性快速恢复。