分布式日志-从Bookkeeper开始
分布式日志是部分分布式系统实现中的基础设施。如果一个系统具备一个完备的分布式日志,辅以订阅等能力,那么这个系统就可以实现很多高级功能,比如分布式事务、分布式快照、分布式复制等。在许多系统中,如Kafka,Pulsar等消息队列实现分布式组件之间的同步。
但对于更基础的分布式实现中,直接使用MQ会引入额外的复杂度,因此我们需要一个更加基础的分布式日志。Bookkeeper通过一定的开发可以快速构建一个分布式日志,本文主要围绕Bookkeeper展开。
分布式日志的基本要求
分布式日志=分布式+日志,其核心其实就是以下几个功能。
- 分布式:
- 多副本能力:保障系统的可用性与容灾性。
- 扩缩容:保证系统的拓展性。
- 日志:
- Append:高吞吐与低延迟的尾部写入。
- Seek And Read:提供从任意位置开始读的能力。
从Bookkeeper开始
Bookkeeper 是当前应用最广的日志存储系统,基于JAVA实现,类似于HDFS的块存储系统以及类似于Pulsar的消息队列都是基于Bookkeeper开发的。
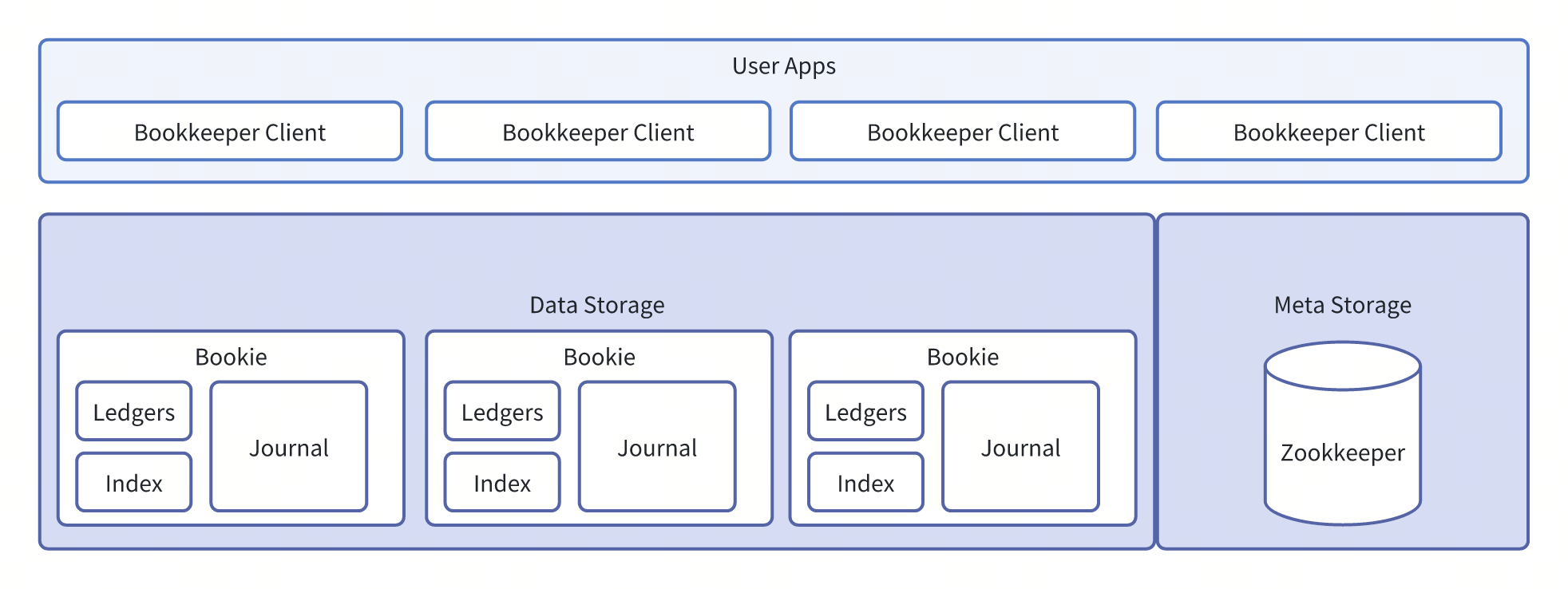
Bookkeeper架构
Bookkeeper是通过Client协调实现的分布式系统,是个Leaderless系统,其主要功能由三个部分构成:
- Client:Bookkeeper的客户端,负责请求与分布式层面协议的实现。
- Bookie:Bookkeeper的存储单元,负责存储数据,本身是一个基于日志的存储服务。
- Journal:Bookie的Write-Ahead-Log,保证高吞吐低延迟的Append能力,Journal的写入一般都配置为同步操作,所以能保证写入操作的原子性。Journal会在Ledgers的异步操作结束后,按照checkpoint快速推进与清理。
- Ledgers:Ledger是Bookkeeper的日志管理单元,其中包含两个部分,Entry Log和Index。其写操作均为异步操作,因此不会影响系统的延迟(可以类比于LSM的SSTable,只不过存储是日志,而不是KV)。
- Entry Log:按照配置多个Ledger会混合在一个日志下,后续通过compaction合并清理。
- Index:基于RocksDB实现的索引文件,保证快速的Seek能力。
- Meta Storage:高可用的存储服务,当前实现为Zookeeper。
其他的诸如Auto-Recovery等组件不属于基础组件,这里暂不做讨论。
有界日志Ledger
Entry
- Entry是Bookkeeper最小的日志单位,每个Entry都存储在唯一的Ledger中,并且用于一个从0开始自增的EntryID作为唯一索引。
- Entry在Ledger中按照EntryID有序稠密的排列。
Ledger
Bookkeeper提供的日志单元式Ledger,一个Ledger是一个有界的日志,即不可能无限增长,其生命周期是有限的,并且按照几个操作行为进行状态迁移:
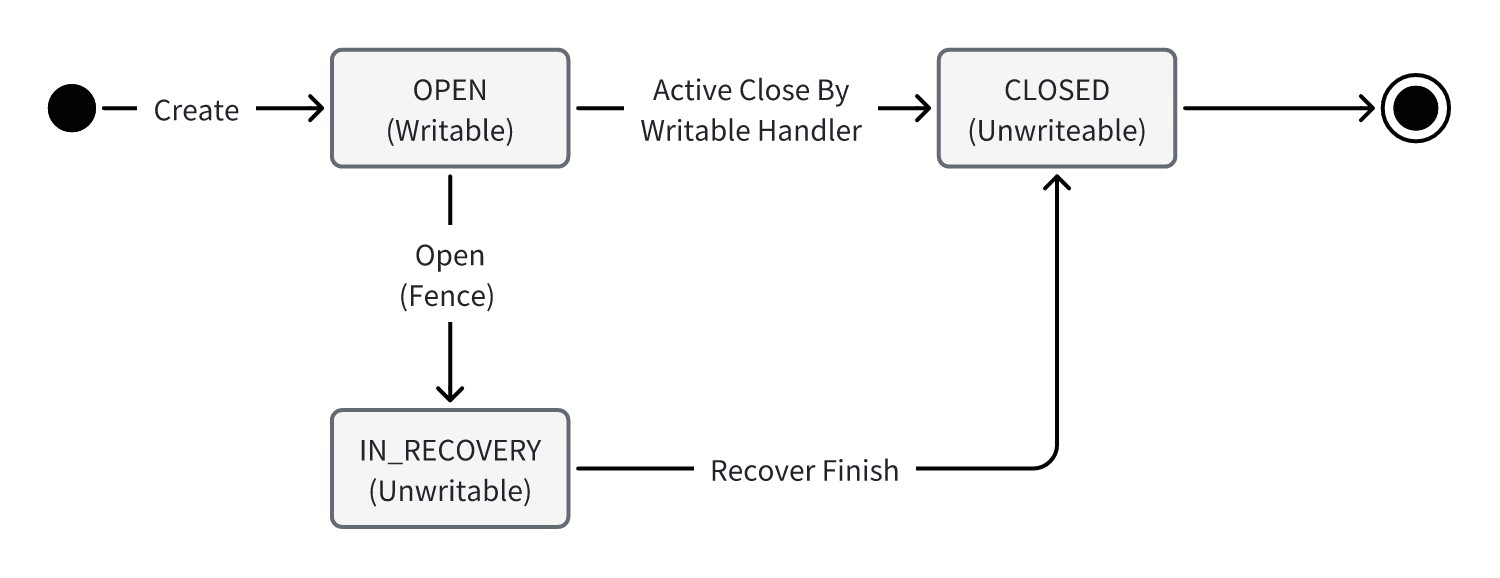
- Ledger是通过CreateLedger创建WriteHandler,其生命周期中只允许该WriteHandler执行写入。只有OPEN状态的Ledger是可写的。
- Ledger的生命周期的终结有两条路线:
- WriteHandler主动的Close。
- Bookkeeper客户端通过Open接口创造ReadHandler造成的恢复操作,也就是所谓的Fence。
- 通过Fence机制,WriteHandler对应的有效写操作能够保证Happen Before后续的ReadHandler的读操作。
Replicas
Ledger这一层已经具备多副本能力,其不同的副本会分散在不同的Bookie上,其副本数量是通过配置的参数决定的,副本数量决定了系统的可用性与容灾能力; 这些参数在Ledger被创建时确定:
- Ensemble(E):表达一个Ledger可以分布到多少个Bookie上。
- Write Quorum(W):表示一个Entry的副本数量。
- Ack Quorum(A):表示一个Entry在写入时,要求有多少个Bookie响应成功。
- 并且满足 $E≥W≥A$
- Ledger在生命周期中可能由于已选的Bookie不可用,出现Ensemble change,导致存储的Bookie列表变更;变更结果会存储在Meta Storage中。
- Entry在Bookie上的分布是通过对EntryID的Hash配合Meta信息确定的。
直接描述可能有些抽象,这里举个例子,比如一个$E=4;W=3;A=2$的Ledger,其Entry在Bookie上的分布可能是这样的:
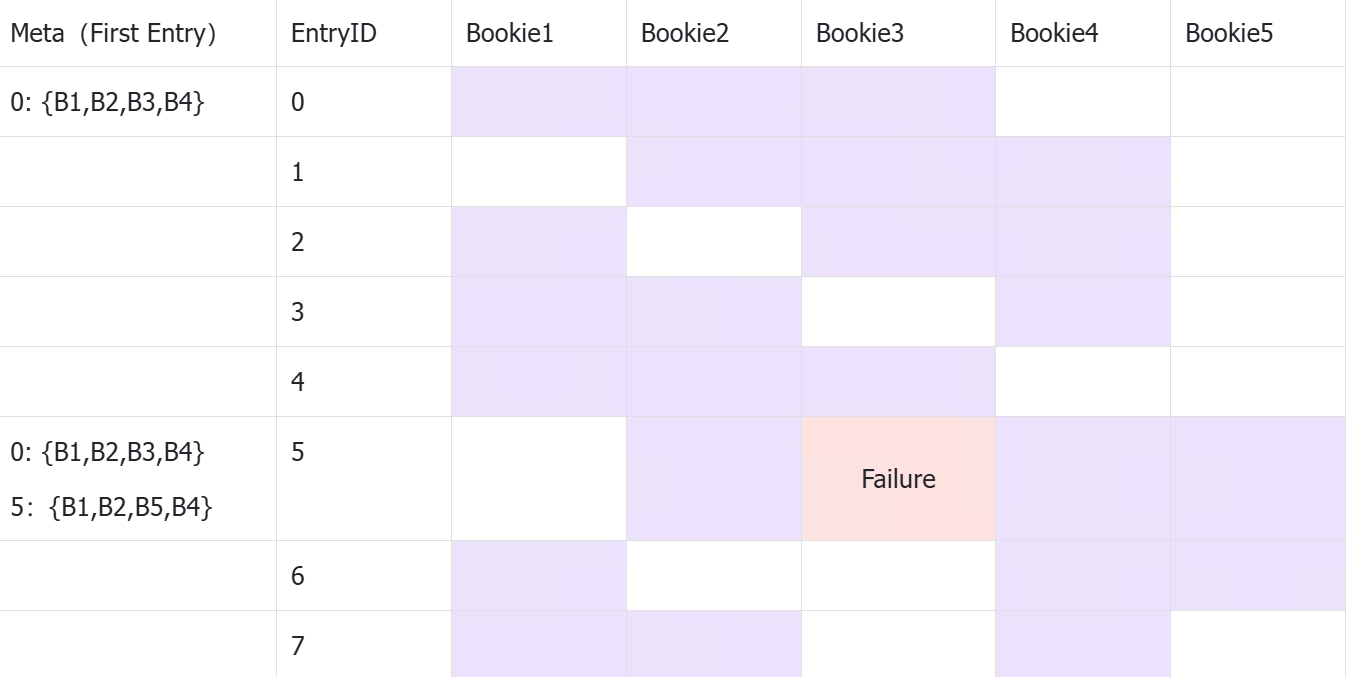
- 该Ledger允许在4个Bookie上存储,每个Entry有3个副本,写入时需要2个Bookie响应。
- 初始化时,选中了B1、B2、B3、B4作为存储节点。
- 通过对EntryID,Hash确定了Entry在Bookie上的分布,比如Entry1在Bookie1、Bookie2、Bookie3上存储。
- 在EntryID=5时,B3出现了写入失败,出现了Ensemble Change,B3被替换为B5。
- Entry5之后的Entry会在B1、B2、B5、B4上存储。
复制协议
读链路上往往只要和单个节点交互;复制协议主要影响的是写链路,所以该节内容,我们都会忽略读相关的工作。 复制协议的核心是共识问题,在Bookkeeper中可以分成两种场景:
- 在系统正常运行的情况下,一个Ledger的WriteHandler全局唯一,只存在一个写角色,因此不存在共识问题,当前的WriteHandler就是该Ledger的Leader。
- 在系统出现了Fence的情况下,发起Fence的ReadHandler需要处理Recovery,Ledger此时存在两个写角色(原来的WriteHandler与新发起的RecoverReadHandler),需要处理脑裂问题达成共识。
因此复制协议的核心处理逻辑发生在场景2中,在出现Fence的情况下,我们自然希望RecoverReadHandler取代WriteHandler成为唯一的写节点,并且完成Recovery。 实现这个目标的核心是Quorum Protocol,即多数者原则,并利用多数者原则在尽量少节点(高可用)的响应情况下得到共识(一致性)。
核心Quorum
| Quorum | 计算方式 | 生效操作 | 备注 |
|---|---|---|---|
| WQ | Write Quorum | Append | |
| AQ | Ack Quorum | Append/Recover | 即写WQ个节点,至少返回AQ个节点。 |
| QC (Quorum Coverage) | (WQ-AQ)+1 | Recover | 保障单个Entry的一致性; 即有QC个节点返回结果,保证其中至少一个节点在AQ内。(一个Entry只有一个AQ集合) |
| EC(Enssemble Coverage) | (Enssemble-AQ)+1 | Fence | 保障Ledger级别的一致性: 即有EC个节点返回结果,保证任意一个AQ选择都包含一个EC。(一个Ledger有多个AQ集合,因为有多个Entry) |
解决脑裂-Fence
第一步:RecoverReadHandler取代WriteHandler成为唯一的写节点;本质就是希望原本WriteHandler能够被禁写并且被感知。
如图Enssemble=4,Ack Quorum=2的情况,可计算出EC=3
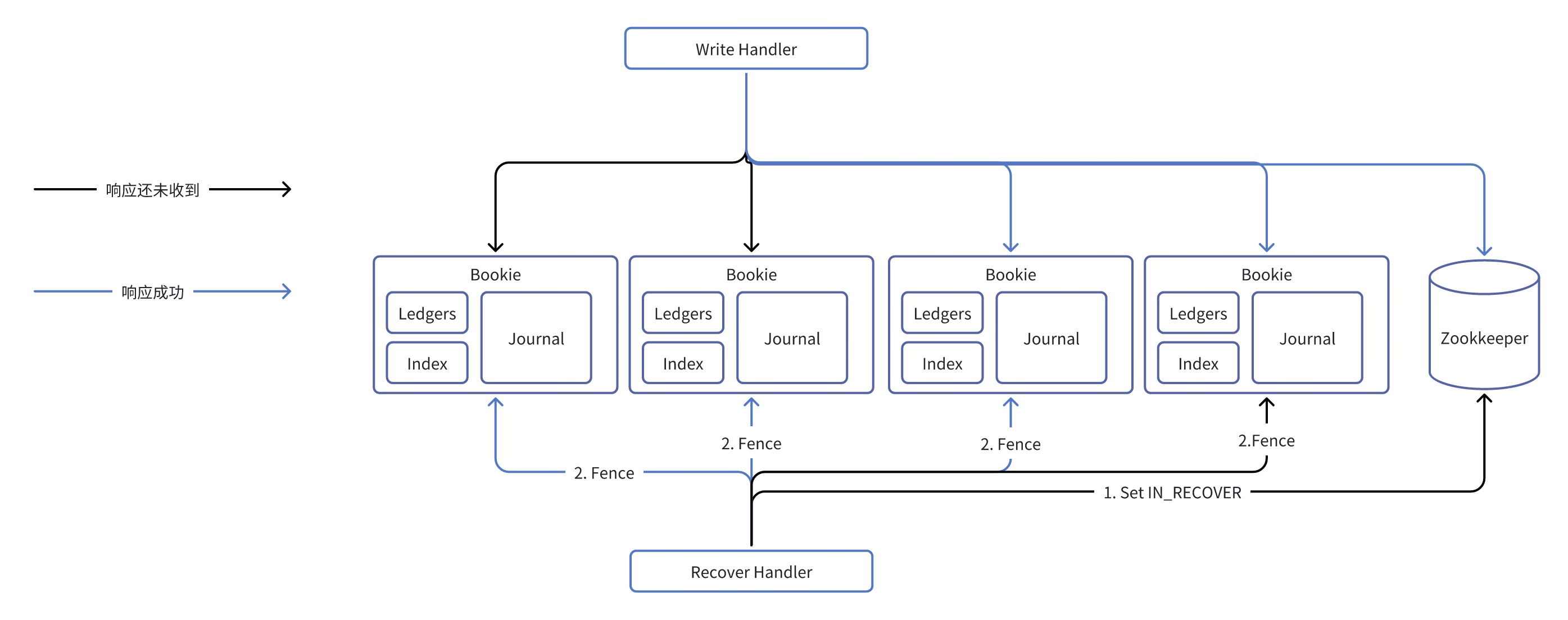
- RecoverReadHandler先通过对Meta状态迁移到IN-RECOVERY状态,来保证WriteHandler无法再修改Enssemble Group
- RecoverReadHandler对Enssemble Group的所有节点发出Fence要求,要求所有节点禁写对应的Ledger,其中只要求EC个节点返回成功,保证了WriteHandler的任意一个AQ Group都包含一个被Fence的节点。从而保证了在EC节点返回Fence成功之后,WriteHandler无法再做任何一个满足AQ要求的写操作,即实现了WriteHandler的禁写。
Recover
在解决完脑裂之后,RecoverReadHandler需要解决数据的Recovery问题(比如WriteHandler早就挂掉了)。
以下为Write Quorum=3,Ack Quorum=2的情况,可计算出QC=2。
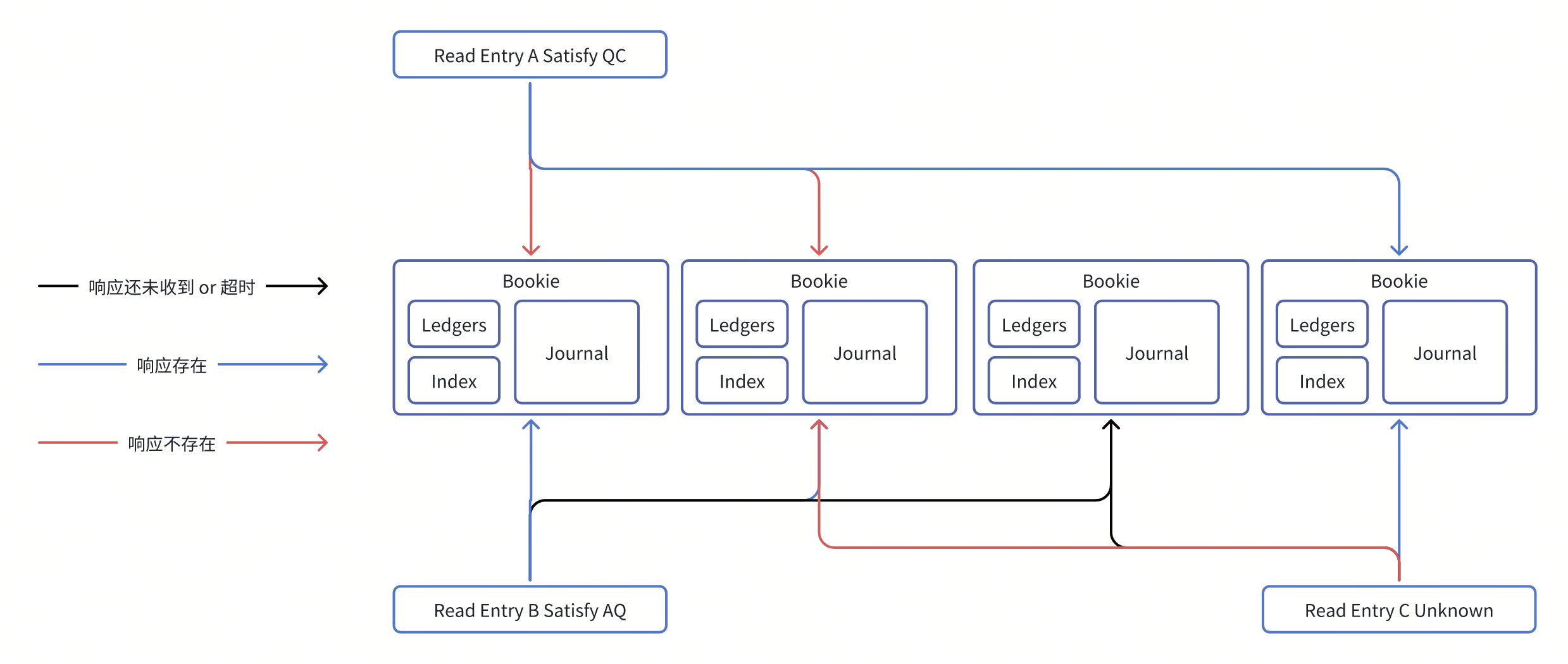
- Meta中持久化有LastConfirmed(LC),以及Entry Log中也持久化有LC(反应WriteHandler最后一次Commit的有效EntryID),
- RecoverReadHandler从LC+1开始修复数据,请求对应WQ的Bookie,如果对应的Bookie存在Entry,则响应存在 ;不存在该Entry,则响应在不存在;典型存在以下几种情况:
| 响应情况 | Entry是否commited | 处理方式 | 对应图中 |
|---|---|---|---|
| QC个节点响应失败 | 否 | 截断到EntryID-1的位置,同时关闭该Ledger (状态从IN_RECOVERY到CLOSED),恢复完成。 |
Read Entry A |
| AQ个节点响应成功 | 是 | 继续Recover流程。 | Read Entry B |
| 其他 | 未知 | 终止Recover流程。 | Read Entry C |
可用性
通过多副本能力,Bookkeeper提供了容灾能力,我们进一步讨论一下各个场景下的可用性。
针对$E=3;W=3;A=2$的场景,集群中一共有4个Bookie的场景,其中一个Bookie出现了宕机或者网络隔离。
| Operation | 可用性 | 说明 |
|---|---|---|
| Create | Y | E=3,剩余的Bookie数量大于3 |
| Ensemble Change | Y | E=3,不可用的Bookie可以被多余的一个Bookie替换 |
| Read | Y | A=2,至少一个节点还有数据可用 |
| Append On Exist Write Handler | Y | 同Ensemble Change |
| Close By Exist Write Handler | Y | Zookkeeper可用 |
| Close By Recover Handler(Fence) | Y | EC=(E-A)+1=2,因此每个Ensemble至少还有EC节点可以返回fence操作结果 |
| Recover | Maybe | QC=(W-A)+1=2,AQ=A=2;可能在恢复某个Entry时,存在上一节中 Read Entry C的情况 ; 如果没有发生,则可用;否则不可用,需要等待恢复。 这是一致性与可用性的trade off |
扩缩容
扩容
- Bookie可以通过增加节点,实现大规模的扩容。
- 此外,Bookie可以通过对LedgerID哈希,来支持挂载多目录,增加磁盘来提升单节点吞吐能力。
缩容
Bookkeeper是基于客户端协调的分布式系统,因此Bookie的扩缩容并不能自动Balance存量的数据。
- 直接下线Bookie节点的行为是危险的,会使整个系统的容灾能力降级(A=2的系统,最多容忍一个节点临时下线)。
- 虽然有运维工具可以迁移,但是采用将目标Bookie节点转为Read-Only,等待上面的文件清理干净再下线是更为安全的做法。